
前回までのあらすじ
バンナムフェスでめちゃくちゃ推しが増えました。エアバス(@airbus_P)です。
前回の記事ではアイドルマスターミリオンライブ!に登場するアイドルの所恵美と高坂海美を見分ける画像分類器を作るべく、準備として学習用の画像を集めました。
今回はそれらの画像を使ってKerasによる深層学習に取り掛かります。
今回の環境
半分ハードの自慢です
ハードウェア
- CPU: Intel Core i7-8086K
- GPU: NVIDIA GeForce RTX2070(VRAM 8GB)
- RAM: 16GB
ソフトウェア
- Windows 10 Education
- Python 3.6.8
- 最新の3.7.4を使ったところTensorflow-gpuが動きませんでした
- tensorflow-gpu 1.14.0
- CUDA 10.0
- cuDNN v7.6.3
- PowerShell
- WSL上のUbuntuを使う事も考えましたが、WSLからはGPUを使えないため断念
深層学習のコードを書く
正直これ以上の導入を書きようが無いので、今回書いたコードを載せておきます。
冒頭のimport周りはもっと整理できそうですね…。
Kerasが使うVRAMの量を制限する
まず最初にKerasが確保するVRAMの量を制限しています。
# GPUのVRAM使用量を80%に制限
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.8
sess = tf.Session(config=config)
K.set_session(sess)
これを行わないとVRAMのほぼ100%を確保してしまうので動作が不安定になります。
なお制限を厳しくしすぎるとデータセットの大きさやバッチサイズの設定によって、VRAMが不足することがあります。その場合はエラーメッセージでその旨が表示されるのでうまく調整してください。
パラメータの設定
batch_size = 128
epochs = 100
train_data_dir = "./images/"
ここではバッチサイズ・epoch数・学習データのあるディレクトリを指定しています。
深層学習では学習時に内部的にデータセットをサブセットに分割するのですが、そのサブセット一つあたりのデータ数をバッチサイズで指定します。
バッチサイズを上げると
- 一つ一つのデータへの反応が小さくなる
- 1epochあたりの学習時間が小さくなる
- 使用するメモリ量が増加する
といったことが起きます。
最初はもっと小さな値を設定していたのですが、やけにLoss値のブレが大きく、学習があまり進まないように思われたので少し大きくしています。
epochsは学習でデータセットを読み込む回数を示します。普通1epochでは学習が十分に進まないため、同じデータセットを繰り返し読み込ませることになります。
この値が小さすぎると学習が不十分、大きすぎると過学習となり失敗に繋がる、調整が難しいパラメータなのですが、今回は後述のearly stoppingを用いるため適当に大きな値を設定しておきます。
データセットを読み込む
# データセットを読み込む
# 2割をvalidationに使用
train_datagen = ImageDataGenerator(validation_split=0.2,
rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(100, 100),
batch_size=batch_size,
class_mode="binary",
subset="training")
validation_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(100, 100),
batch_size=batch_size,
class_mode="binary",
subset="validation"
次にKerasのImageDataGeneratorを使ってデータセットを読み込んでいます。
Kerasで画像を学習していくときには、その画像を4次元配列配列とし、さらに値を0.0-1.0の範囲に変換する必要があります。
もちろんNumPyとfor文やwhile文を使って自分で処理してもいいのですが、KerasのImageDataGeneratorを使うと、ディレクトリを指定すれば自動的にラベルを付けたりリサイズをすることもできてとても楽です。
ラベルを付けるにはラベルの名前のサブフォルダに画像を分類して入れておきます。(今回は下図のようになる)
images
├ megumi
│ ├ megumi_00.jpg
│ ├ megumi_01.jpg
│ └ ...
└ umi
├ umi_00.jpg
├ umi_01.jpg
└ ...
今回はデータセットのうち2割を検証用(学習には使わず学習途中の進み具合を確認する。最終的な学習結果を確認するテスト・検証とは別)に使うことにし、検証用データの抜出しはImageDataGeneratorに任せることとします。
# データセットを読み込む
# 2割をvalidationに使用
train_datagen = ImageDataGenerator(validation_split=0.2,
rescale=1./255)
ここでvalidation_split=0.2とすることでデータセットの2割を検証用とし、rescale=1./255とすることで配列の値を0.0-1.0の範囲に変換しています。
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(100, 100),
batch_size=batch_size,
class_mode="binary",
subset="training")
validation_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(100, 100),
batch_size=batch_size,
class_mode="binary",
subset="validation"
その後サイズを縦横100pxに指定して、学習・検証用データを読み込みます。
今回は恵美と海美の二値分類を行いたいので、class_modeはbinaryを指定します。(0が恵美, 1が海美)
モデルを定義する
次にモデル、つまりニューラルネットワークの形を定義していきます。
正直どんなモデルにすればいいのかはよく分かっていないので半分勘でやっています。
# モデルを定義
model = Sequential()
model.add(Conv2D(24, (3, 3), padding='same',
activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(48, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(96, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.summary()
adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999,
epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam,
metrics=['acc'])
一応解説しておくと
Conv2Dでは画像の畳み込み(≒フィルタリング)を行い、特徴量を抽出しています。
MaxPooling2DではConv2Dで作った特徴量マップをダウンスケールします。これは畳み込みを繰り返すと学習が困難になったり、過学習に陥ったりするため、それを回避する目的があるようです。
Dropoutではノードを一定割合で不活性化させることで過学習を回避し、精度を上げようとしています。
二値分類を行うときには活性化関数をsigmoid、損失関数をbinary_crossentropyにするのが普通との記述を色々なページで見たので、その通りにしています。
画像を二値に分類するサンプルとしてはイヌとネコの判別がよく使われており、今回の実験でも参考にしました。
それに比べると今回のデータセットはキャラクターの顔だけをトリミングしていることもあり、かなり似たものも多いため過学習になりそうという不安が強く、MaxPooling2DやDropoutを多めに入れています。
この部分は本当に理解せずやってるのでご意見お待ちしています。
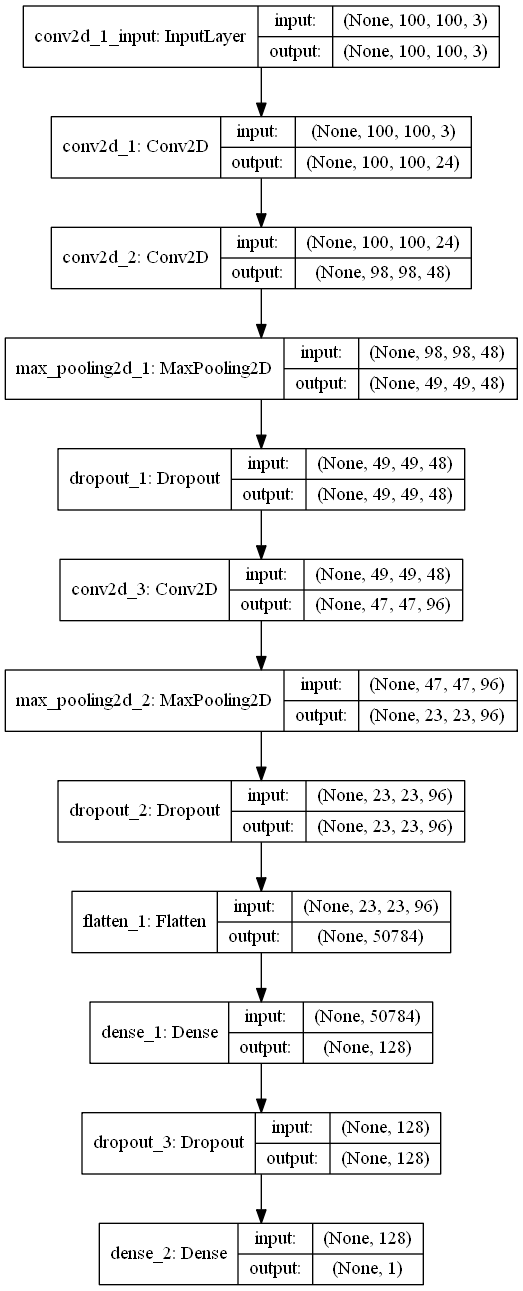
ここで作ったモデルは構造を図表化して保存しておくことができます。
keras.utils.plot_model(model, to_file='model.png', show_shapes=True)
Early Stopping
深層学習では必要以上に学習を繰り返すと過学習に陥り、学習用データにだけ最適化され、新規のデータに対応できないモデルができてしまいます。そのため、適切な回数で学習をやめることが必要です。
そんなときに便利なのがEarly Stopping。
val_lossやtrain_lossといった指標を監視し、値が改善しなくなった時点で学習をやめるという機能です。
callbacks.append(keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1, mode='auto'))
callbacks.append(keras.callbacks.ModelCheckpoint('epoch'+str(epochs)+'_best_weights.h5', monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=True, mode='auto', period=0))
ここではval_lossを監視し、10回連続で値が改善しなかった(つまり減少しなかった)時点で学習を止めるよう設定しています。またkeras.callbacks.ModelCheckpointではval_lossが改善したタイミングで、それまでに学習した重みデータを保存するようにしており、Early Stoppingが働いた時点での学習の成果を保存することが出来ます。
学習開始・学習曲線の画像化
# 学習開始
history = model.fit(
train_generator,
verbose=1,
validation_data=validation_generator,
epochs=epochs,
callbacks=callbacks
)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
# =========== 中略 =============
import seaborn as sb
sb.set()
epochs_plt = range(1,len(acc) + 1)
plt.plot(epochs_plt, acc,"r",label="Training Acc")
plt.plot(epochs_plt, val_acc,"b",label="Validation Acc")
plt.legend()
plt.savefig(str(epochs)+"_acc.png")
plt.figure()
plt.plot(epochs_plt,loss,"r",label="Training Loss")
plt.plot(epochs_plt,val_loss,"b",label="Validation Loss")
plt.legend()
plt.savefig(str(epochs)+"_loss.png")
学習を行うfit()の戻り値historyには学習の履歴(accやloss)が記録されており、それらをmatplotlibを使ってグラフ化することで、学習曲線を見る事ができます。
matplotlibデフォルトのデザインだと如何せん見づらい部分が多く感じたので、今回はseabornというライブラリを使って見た目を整えています。
学習結果
上記のデータで学習を行ったところ、
Epoch 00018: val_loss did not improve from 0.01713
Epoch 19/100
54/54 [==============================] - 4s 73ms/step - loss: 0.0136 - acc: 0.9948 - val_loss: 0.0344 - val_acc: 0.9895
Epoch 00019: val_loss did not improve from 0.01713
Epoch 20/100
54/54 [==============================] - 4s 76ms/step - loss: 0.0075 - acc: 0.9975 - val_loss: 0.0233 - val_acc: 0.9948
Epoch 00020: val_loss did not improve from 0.01713
Epoch 00020: early stopping
-----------------------------------------------
Finished. Time: 83.44836810000001
20回目にして学習が止まってしまいました。
流石に早すぎるのでは?と思い何度かやり直したものの大きな差は出なかったため、これで学習が終わっているようです。
学習曲線はこのような形になりました。
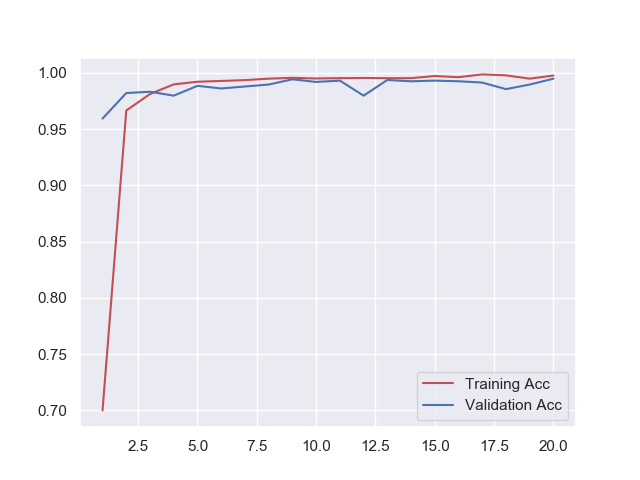
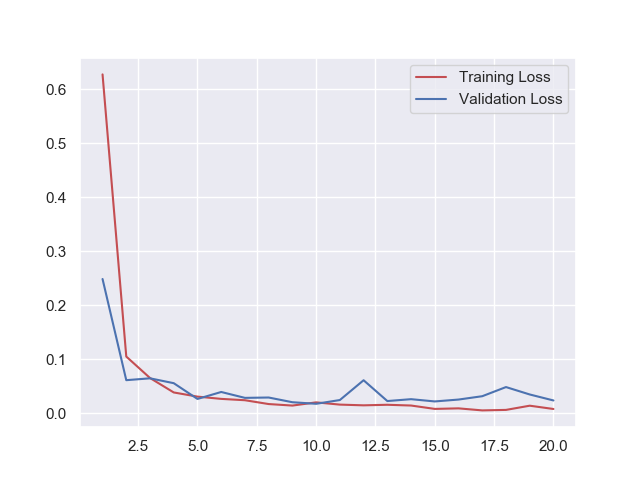
学習曲線やAcc, Lossの数値を見ても特に学習不足や過学習に陥っている様子は無いので上手く学習ができたのでは無いでしょうか?
テストしてみる
学習がおそらく成功したので、この学習済みのモデル・重みを使い、全く訓練に使っていない画像についてどのくらいの精度で海美と恵美を判別できるのかテストしていきます。
今回は訓練データに使ったのとは別のMVやゲーム内イラストから計1223枚の画像を作成し、判別の成功率をテストしました。
結果は下記の通りです。
Found 1223 images belonging to 2 classes.
1223/1223 [==============================] - 5s 4ms/step
Test loss: 0.14352468358373527, Test acc: 0.9337694194603434
正解率93.37%とまあまあ悪くない精度が出ているのではないでしょうか。
ひとまずは海美と恵美を見分けるという課題は解決しました。
ここで少し気になったのが、「爽快ウィンドサーファー 馬場このみ」のカード画像をこの分類器は海美と恵美どちらに分類するのかという点です。

僕は初見で海美のカードだと思いました。(ごめんなさい)
という訳で一枚の画像を読み込んで、その分類先と確率を表示するコードを書きました。(確率の考え方があってるのかやや不安はあります)
これにカード画像の顔を切り出した正方形の画像を読み込ませます。

結果
これは恵美です。確率: 56.100%
というわけでこの分類器はこのみさんの顔を「どちらかといえば恵美っぽい」と判断したようです。
確率56.1%と判断しているのも、そもそも与えた画像が海美でも恵美でも無いのでかなり良い感じなのではないでしょうか。
これから
というわけで海美恵美判別器が完成しました。
これによって幾千ものミリマス初心者が救われることでしょう。
ここからはAugmentationによる学習用データの水増しや、Fine Tuningを使って精度を上げる事ができるか試していきます。また余裕があればWebサービスとしても公開するかもしれません。