
前回までのあらすじ
こんにちは。
最近声優さんのInstagramを見ることが生きがいになっているエアバス(@airbus_P)です。
前回の記事では、ひとまず海美と恵美を判別する画像分類に93%の精度で成功しました。
しかしどうせなら、もっと高い精度を目指したい!という事で今回はData Augmentationと呼ばれる手法を使ってみます。
Data Augmentation(データ拡張)とは
Part 1でも述べた通り、機械学習を行う上では学習に用いるデータ数を確保することがポイントとなります。
データが少ないと過学習に陥り、学習データにだけ最適化され、新たに与えられたデータには対応できない使いどころのない人工知能が出来上がってしまいます。
とは言え、大量の画像を用意するのはなかなか骨が折れるもの。そこで用いられる手法の一つがData Augmentationです。
Data Augmentationでは画像に反転や明度の変更、平行移動などの加工を加えて、画像の水増しを行います。これにより全く同じデータを学習する回数が減り、過学習を避けやすくなります。
せっかくAdobe CCに加入しているのでLightroomやPhotoshopを使って画像の水増しをしても良いのですが、さすがに4桁枚もの画像を扱うのは厳しいので、今回はKerasのImageDataGeneratorの機能を利用して画像を水増しします。
ImageDataGenerator
前回はこのImageDataGeneratorをデータセット読み込みと画像の配列化に使いましたが、実はData Augmentation用の機能も含まれています。
詳しくは公式ドキュメントにまとまっていますが、
- 回転
- 水平移動
- 垂直移動
- チャンネルシフト(目で見た感じは明度やコントラストの変化しか感じられない)
- 拡大
- 反転
などをランダムに行うことができます。
今回はキャラクターの顔だけを切り抜いた正方形の画像を使っていくので、
- 水平・垂直移動
- チャンネルシフト
- 水平方向の反転
の三つをかけて画像を水増ししてみました。
コード
というわけでコードを書きました。
簡単に解説を加えます。
args = sys.argv
arg_n = len(args)
if arg_n > 2:
raise RuntimeError('ディレクトリを一つだけ指定してください')
elif arg_n < 2:
raise RuntimeError('画像を読み込むディレクトリを指定してください')
base_path = os.path.dirname(os.path.abspath(__file__)).replace("\\", "/")
input_dir = base_path + "/" + args[1] + "/"
if not os.path.isdir(input_dir):
raise RuntimeError('ディレクトリが見つかりません')
output_dir = input_dir + "/aug/"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
ここでは引数で画像のあるフォルダを指定し、その下に加工後の画像を保存するフォルダを作成しています。
replace("\\", "/")としているのは、Windowsのパス表記に対応するためです。
fileExtensions = ["jpg", "jpeg", "png"]
input_img = []
for ext in fileExtensions:
input_img.extend(glob.glob(input_dir + "*." + ext))
files = [a.replace("\\", "/") for a in input_img]
ここではinput_dirから、リストfileExtensionsに含まれる拡張子を持つファイル名をリスト化しています。単なる検索だと拡張子が混在するファイルの扱いが大変そうでしたが、配列を使ったらどうにかなりました。
(Pythonのfor文は遅いので使うべきではないらしいですが、僕はエンジニアでは無いので動けば良しとします)
datagen = ImageDataGenerator(
channel_shift_range=0.74564,
horizontal_flip=0.6,
width_shift_range=0.1,
height_shift_range=0.1
)
少し飛んでここでData Augmentationの設定をしています。
今回はランダムに
- 74.564%の範囲内でチャンネルシフトさせる
- 60%の確率で水平方向を反転する
- 横幅の最大10%まで左右方向に水平移動する
- 縦幅の最大10%まで上下方向に垂直移動する
という設定にしています。
for i in range(3):
generate = gen.next()
最後のここで一枚の入力に対する出力の回数を決めています。
今回は1枚の元画像から3枚の加工後画像が保存されます。
加工の様子
どんな加工がされるのか分かりにくいと思うので、試しにテスト用画像でどんな変化が起きるのか見てみます。
▽テスト用画像。瀬戸ファーブと水本ゆかりです。

▽結果。軽く見ただけでも位置や左右の向きが変わっているのが分かります。

ちなみに水平・垂直移動した場合、足りなくなる部分は一番端のピクセルがそのまま水平・垂直にコピーされています。(下の比較を参照)


channel_shift_rangeについてはなんとなく色味が変わっている気がするものの、そこまで分かりやすい違いは見られませんね。
再学習開始
前回まで使っていた約8500枚の画像からなるデータセットから上記のコードを使って、約24000枚のデータセットができました。(なんで三倍になっていないのかは不明。)
ニューラルネットワークのモデルは前回と同じものを使って学習していきます。
としたところ、画像読み込みでPythonに無茶苦茶な量のRAMを使われました。
Pythonが一人でVRAMとRAM食いつぶしてて笑ってる
— Reisalin Stout (@airbus_P) September 10, 2019
一つのアプリでRAM9800MBとか使ってるのアホでしょ
GPUはメモリ制限かけれたから良いけども
GPUもガッツリ動いてて、高いグラボを買った甲斐がありました。(隙あらば自慢)

絶対もっと上手いやり方があるんだろうけど、どうにか動かせたので気にせずに行きます。
学習結果
今回もEarly Stoppingが働き、53epoch目で学習が終了しました。
Epoch 52/150
37/37 [==============================] - 9s 247ms/step - loss: 0.0175 - acc: 0.9974 - val_loss: 0.0263 - val_acc: 0.9903
Epoch 00052: val_loss did not improve from 0.01862
Epoch 53/150
37/37 [==============================] - 9s 248ms/step - loss: 0.0171 - acc: 0.9978 - val_loss: 0.0231 - val_acc: 0.9922
Epoch 00053: val_loss did not improve from 0.01862
Epoch 00053: early stopping
-----------------------------------------------
Finished. Time: 496.1499922
学習曲線もブレが少なく良い感じなのでは無いでしょうか。
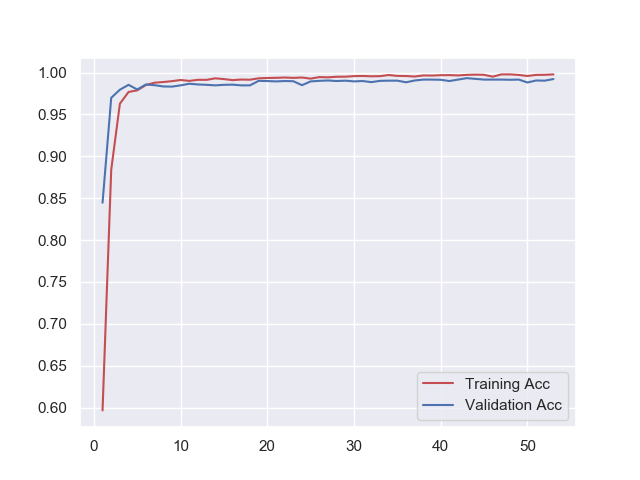
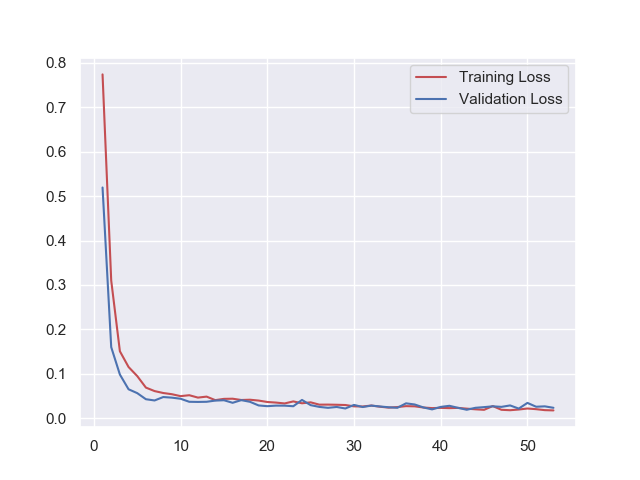
テスト
それではData Augmentationによって精度は向上したのか見てみましょう。
これも前回のコードで読み込む、学習済み重みデータを変えるだけでOKです。
結果は下記の通りになりました。
Found 1223 images belonging to 2 classes.
1223/1223 [==============================] - 10s 8ms/step
Test loss: 0.1274900235474377, Test acc: 0.9574816026165167
正解率は95.75%と前回の93.37%から向上しています。
これはData Augmentationによって精度が向上したと言えるのではないでしょうか。
まとめ
今回はData Augmentationにより、学習データを水増しすることで識別精度を上げることに成功しました。次回はfine tuningによる学習について書く予定でいます。