
はじめに
ナナシスの瀬戸ファーブガチャを回しています。二枚目が来ません。エアバス(@airbus_P)です。
突然ですがみなさんは 「アイドルマスターシャイニーカラーズ」 (以下シャニマス)をご存知でしょうか?
シャニマスはアイドルマスターシリーズの最新作で、283(つばさ)プロダクションのプロデューサーとして個性あふれる所属アイドル達をプロデュースしていくゲームです。
ゲームのシステムとしてはパワプロのサクセスのように毎ターン行動を選んでアイドルのステータスを上げ、オーディションに挑戦してファン数を増やしていくことが目標なのですが、その合間に展開されるコミュのシナリオでのキャラクター描写が本作の魅力の一つとなっています。
そんなシャニマスに登場するアイドル達の中で特に私が気になっているのが風野灯織(かざのひおり)さんです。

(どんな子なのかは上記画像のリンク先(公式サイト)をご確認いただければと思います)
不器用な性格ながらも仲間思いでストイックなクールでかわいく真面目なアイドルなのですが、もっと彼女のことをよく知りたい!
そのために今回は最近流行りの深層学習 -Deep Learning- の力を借りて風野灯織さんの性格をより深く理解したいと思います。
まずはテキストデータ化
まずは今回分析の対象とする風野灯織さんのセリフをテキストデータにする必要があります。
シャニマスはブラウザゲームなので、適当にhtmlソースやHTTPのリクエスト・レスポンスを見ればテキストを抽出できるんじゃね?と思ったのですが、暗号化したテキストをクライアント側で復号してJavaScriptでレンダリングしているようでいまいちよく分からず…(勉強不足なのでこのあたりの記述はあいまいです)
そこでダメ元でゲーム画面のスクリーンショットにGoogleドキュメントのOCR機能を使ってみたところ…

うまくいってんじゃん!!
というわけで今回はひたすらスクショを撮り、OCRによってテキストデータ化していくことにしました。
Cloud Vision APIを使う
とはいえ、数百の画像を片っ端からGoogleドキュメントとして開いていくのは現実的ではありません。
なので今回のOCRにはGoogleが提供するCloud Vision APIを使います。
Cloud Vision APIはAIによる画像分析を提供するWeb APIで、
- 画像の分類
- 顔検出
- オブジェクトの検出
- 活字や手書き文字の検出
といった機能が利用できます。
日本語にも対応しており、1000リクエスト/月までは無料で使用可能、精度も良好という事で今回の用途にはぴったりです。
(無料枠を超えると1.50USD/1000リクエスト。GCP利用開始時に一年間使える300USDの残高がもらえるため、今回のような使い方で課金が必要になることは無いと思われます)
詳しい使い方についてはこちらの公式ページを確認していただくとして、まずは元になる画像を用意します。
素材画像の用意
今回はごく単純に人力でスクショを撮りまくり、灯織さんが話している場面の画像を698枚用意しました。
このままでは文字の認識に不要な部分やセリフ以外の文字が画像内に含まれてしまうため、UbuntuからImageMagickを使って一括でトリミングを行いました。
同じ作業を反復してやるならコマンドラインから使えるツールが結構便利。
$ ls hiori*.png | xargs -I{} convert "+repage" -crop 980x135+470+900 {} cut-{}
結果こんな感じでセリフの枠内だけをトリミングした画像ができあがります。

コードを書いてAPIを叩く
この機会にJavaScript入門しようかと思ったのですが面倒くささが勝ってしまったので今回もPythonです。
基本的にはGCPのマニュアルのサンプルコードをベースに、少し変更を加えただけで上手く動きました。
import re
import glob
image_dir = "/path/to/image_directory/"
img_list = glob.glob(image_dir + "cut*.png")
def detect_text(path):
from google.cloud import vision
import io
import os
# os.path.splitextはファイル名部分を"."で分割して配列を返す
# 0番目の要素を指定すれば拡張子無しのファイル名が取得できる
img_filename = os.path.splitext(path)[0]
client = vision.ImageAnnotatorClient()
# 画像を読み込む
with io.open(path, 'rb') as image_file:
content = image_file.read()
# 画像をBASE64に変換している(らしい)
image = vision.types.Image(content=content)
# 日本語のテキストというヒントを付加
image_context = vision.types.ImageContext(language_hints=['ja'])
# APIを叩いてレスポンスを取得
response = client.text_detection(image=image,image_context=image_context)
# full_text_annotationに認識した文字列の全文が入っている
texts = response.full_text_annotation.text
print(path)
print('Texts:')
print(texts)
# 画像と同名で拡張子のみ変更したファイルにレスポンスのテキスト部分を書き込む
with open(img_filename + ".txt", mode="a") as f:
f.write("\n"+texts)
print("==========================================")
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: '
'https://cloud.google.com/apis/design/errors'.format(
response.error.message))
# 上記処理をforループで回す
for img in img_list:
path = img
detect_text(path)
print("finish")
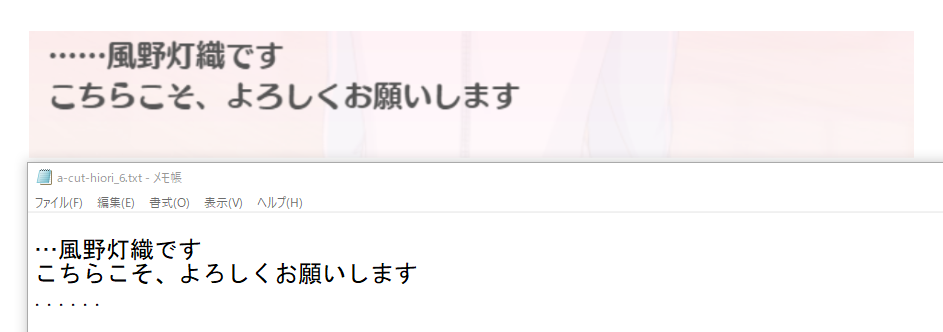
上手くいくと下記のように標準出力に表示され、テキストファイルにセリフが保存できるはずです。

しっかり認識できているようです。
ところでなんでAPIって叩くんですかね?
OCR精度
正直日本語OCRの精度は大したことないと思っていたため、今回実用的な精度が出ていたのはやや意外でした。(特にGoogleドキュメントという無料プロダクトでも同様な点)
基本的には上記画像の通り正しく文字を認識できているのですが、中にはやはり誤認識や無検出を起こしているものが見られました。
一番無検出が多かったのが三点リーダーを中心とした記号類。
これは模様と区別できないので仕方ない気もするのですが、灯織の場合セリフで三点リーダーがよく登場するので少し残念でした。(上記の画像でも誤検出っぽい点が入っている)
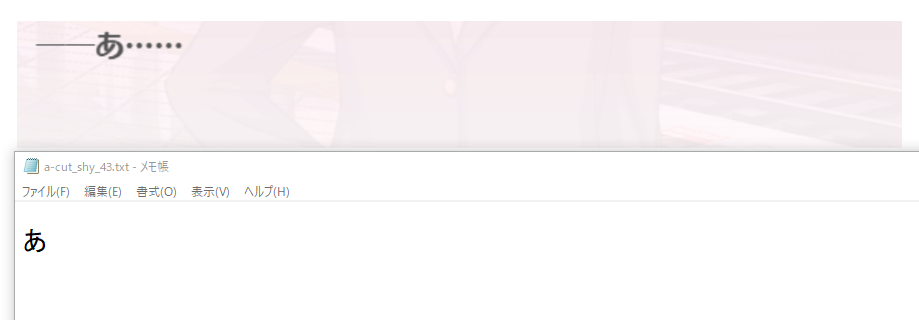
▽典型的な無検出例。文頭のダッシュと文末の三点リーダーが抜けている。
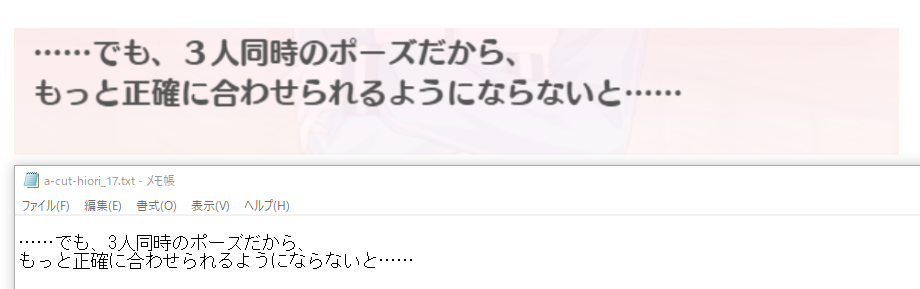
▽長い文で登場する場合は比較的よく検出できているように思われた。
他には数は少ないものの漢字の誤認識が見られました。
e.g. 眩を咳、宛を弘と誤認識する
ただ誤りの数は(気付いた範囲では)かなり少なく、流石はGoogleといった感じです。
Watsonで性格推定
こうして出来上がったテキストを再び深層学習を使い、今度は性格推定を行っていきます。
こちらではIBMの提供する『お客様のビジネスに活用いただくためのAI』(公式ページから引用)であるWatsonの機能の一つ、Personality Insightsのデモページを使います。
こちらも詳しくは公式ページをご確認いただきたいのですが、ざっくりと説明すると、テキストを解析してその書き手のパーソナリティの特性(傾向や価値観、欲求)を推定してくれる性格分析サービスです。
キャラクターのセリフは話し言葉ですが、デモページのサンプルにはスピーチの原稿もあるくらいなのできっと大丈夫だろうと判断しました。
こちらはデモを使うだけならとても簡単で、デモページにアクセスして、テキスト入力タブから「任意のテキスト」を選択し、そこに文章を書き入れるだけで気軽に分析結果を見ることができます。
なお左のタブから自分のTwitterアカウントのツイートを読み込ませることもできるので試してみてはいかがでしょうか。
というわけで早速今回用意した灯織のセリフを入力した結果がこちら。
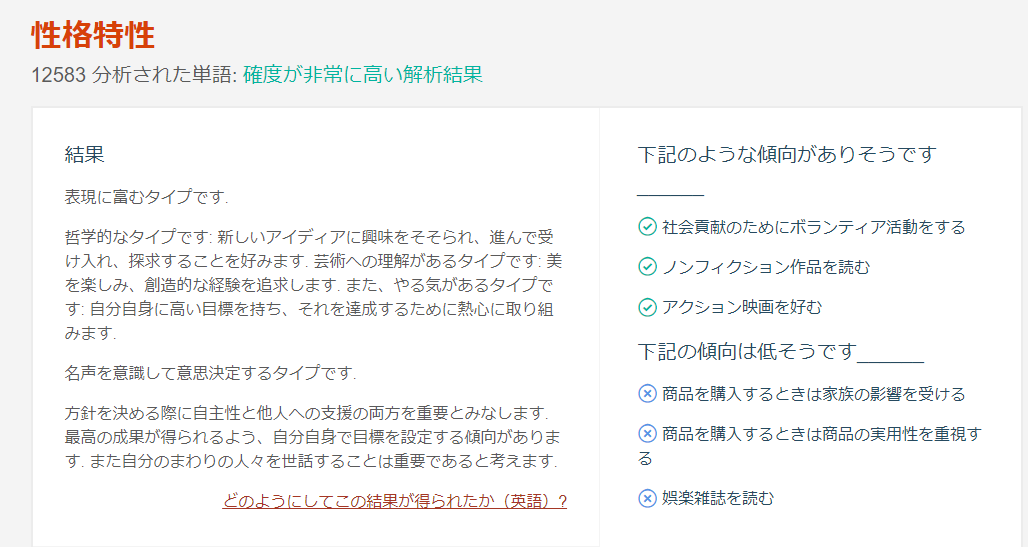
13000語弱の単語が検出されており、推定には十分なデータ量が確保できているようです。
- 表現に富む
- 芸術への理解がある
- やる気がある
- 自主性と他人への支援の両方を重要とみなす
- 自分自身で目標を設定する
- 周りの人を世話するのを重要と考える
この辺結構当たってる気がしません?
- アクション映画を好む
- 商品の実用性はあまり重視しない
あたりはそうかな?という感じがしますが…
より細かく要素ごとの傾向の強弱を見ることもできます。
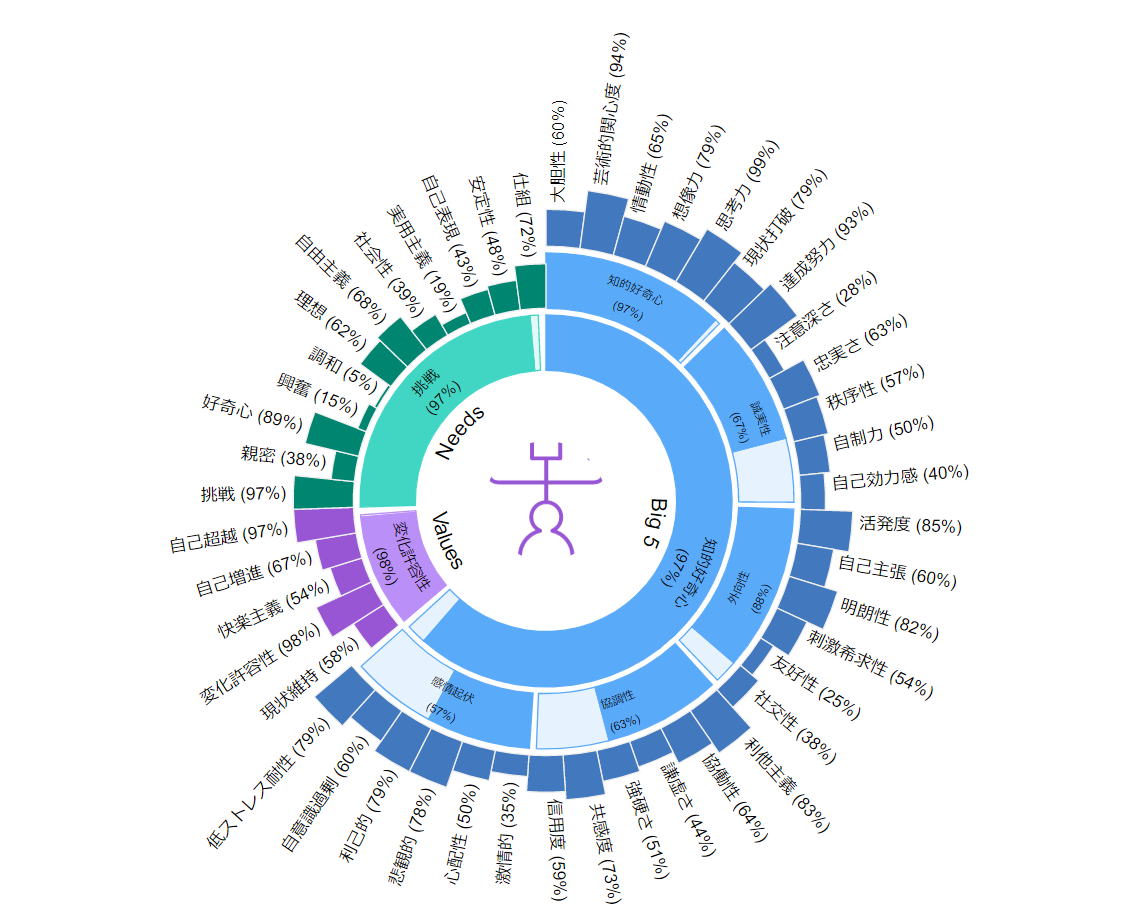
ここでいうパーセンテージは他の人々と比べたときの相対的な強弱を表しています。(例えば自意識過剰が60%の時は、100人中その人より自意識が強い人が40人、弱い人が60人いるということを意味する)
まずはぱっと見て明らかにずば抜けている物を抜き出してみます。
- ビッグファイブ(個性)
- 思考力 99%(新しいアイデアへの寛容さ)
- 芸術的関心度 94%(美しいものが好きで、創造的経験を求める)
- 達成努力 93%(自分に高い目標を設定し、その達成のために真剣に取り組む)
- ニーズ(欲求)
- 挑戦 97%(達成、成功、挑戦への欲求がある)
- 好奇心 89%(発見、調査、成長への欲求がある)
- バリュー(価値観)
- 変化許容性 98%(独立した行動、考え方、感覚を重視し、新しい経験を進んで受け入れる)
- 自己超越 97%(他人の幸福や利益を気遣う)
注)各項目の説明はPersonality Insightsのドキュメントページを参考に記述しました。
…結構当たってるのでは?(バーナム効果)
特に挑戦とか努力といったストイックさや「独立した考え方を重視する」あたりに灯織ズムを感じます。
あと他人の幸福や利益を気遣う傾向がかなり強いのもいいですね。
他に数値が高い項目で気になったのが
- 情緒不安定性
- 低ストレス耐性 79%(ストレスにうまく対処できない。プレッシャーがかかったり、緊急事態に直面したりすると、パニック、混乱、無力の状態になる。)
- 悲観的 78%(罪悪感、悲しみ、絶望、または孤独の感情を抱きやすい)
強かになってきているけど、元はストレスに弱かったり悲観的だった印象ありませんか?
逆に数値が低い項目を見ると
- ビッグファイブ(個性)
- 注意深さ 28%(行動する前に、注意深く可能性を考え抜く)
- 友好性 25%(人が好きで、その感情をオープンに表す)
- この項目はデモページの翻訳が不自然なようで、英語では"friendliness"(気安さ)となっています
- ニーズ(欲求)
- 調和 5%(他の人たちを理解し、他の人たちの観点や感情を尊重する)
- 興奮 15%(現実から飛び出して人生を送りたい、陽気で感情豊かであり、楽しむことが好き)
- 実用主義 19%(任務をこなしたい欲求があり、スキルと効率性 (身体的な表現や経験も含まれることがある) を望む)
なんか半分くらいしか当たってないような気が…
「感情をオープンに表す」「現実から飛び出して人生を送りたい」あたりが低いのはWING編の序盤の方や、【清閑に息をひそめて】のコミュから割と感じ取れるのですが、行動する前に可能性を考え抜く傾向は【落下予測地点】を見る限りかなり強そうな気がするし、仲間思いで調和への欲求も強そうだと思うんだけど…
あまり当たっていない部分を含めて「実はそういう傾向なのかも知れない」と考えたりするのも面白いかもしれません。
注)このサービスはビジネス・マーケティング用途を前提としたもので、心理学・医学的な診断に用いることは想定されていない点にお気を付けください
終わりに
というわけで今回はOCRでシャニマスのシナリオをテキストファイル化して、灯織の性格推定に使ってみました。
ひとまず人力を活用してシャニマスのシナリオをテキスト化する手法は見つけられたので、これから色々できるかも?
性格推定部分は真面目に考えるとどこまであてになるのか分りませんが、結果を見ながら色々なコミュのシナリオを考えるのは結構面白かったです。
余談
この記事が気になった方には以前書いた深層学習で海美と恵美の顔を見分ける記事もおすすめです。