
Slack上の画像を管理者権限が無いのでスクレイピングで保存しまくる
はじめに
4時までCiv6やってからフルタイムでバイトする生活。エアバス(@airbus_p)です。
突然ですがみなさんはSlackをご存じですか?私はとてもよく存じ上げています。
Slackはビジネス向けのグループ内SNSで、BBSのような形で話題ごとに分かれたチャンネルにみんなで投稿していくことができます。
(Discordのビジネス版がイメージに近いですね)
私もいくつかのグループでSlackを利用しているのですが、先日ちょっとしたやりたいことができました。
「このチャンネルに投稿されてる画像、さかのぼって保存してぇ~~~」
はい。色んな人が自分の描いたイラストを投稿しているチャンネルがあるのですが、そこのイラストが素敵すぎるので片っ端から保存したくなった訳です。
こういった需要は結構多いらしく、軽く検索をかけてみたところいくつかの解説記事を見つけました。
しかし1つ問題が。それらはどれもSlackの公式APIを使っているのですが、私は「保存してぇ~~~」となっているチャンネルの管理者権限を持っていないため、公式APIを使うことができないのです。
ところで意外と知られていないのですが、SlackはPCにアプリをインストールせずともWebブラウザから利用することが可能です。
ならばWebからスクレイピングをすればいいのでは?
ということで今回はWeb版Slackをスクレイピングして画像を保存しまくることに挑戦しました。
注:今回試したSlackのワークスペースは非公開なので、記事内のスクリーンショットやコードはURLなどを一部改変しています。
準備
処理を考える
コーディングを始める前にまずはどういう処理を行うかを考えておきます。
スクレイピングで画像を抽出する場合、普通は
- ブラウザを操作して目的のページにアクセス、htmlを取得
- htmlを他のツールに渡して解析
- 目的のファイルのURLをhtmlから抽出
- URLにGETリクエストを送る
- 返ってきたファイルを保存
という手順を踏みます。
今回も同じような手順を踏みたいのですが、下記のような問題点があります。
- Slackのページはログインしないと見れない
- 投稿された画像もログイン状態でないとアクセスできない
- 1ページ内の無限スクロールでhtmlの内容が更新されるため、リンクを辿って遡ることができない
これらを解決するためには
- ログイン用のCookieをブラウザ側で保存しておく
- CookieをGETリクエスト送信に使うライブラリにも渡す
- スクロールを自動化する
ことが必要です。
今回はSeleniumというツールでGoogle Chromeを操作してこれらをどうにかしていきます。
ソフトの準備
今回は下記のような環境を用意しました。
- Google Chrome(Stable) 80.0.3987.132
- Python 3.6.8
- selenium 3.141.0
- ChromeDriver 80.0.3987.106.0
- beautifulsoup4 4.8.2
- lxml 4.5.0
- requests 2.23.0
それぞれ軽く説明していきます。
Google Chrome(Stable)
みなさんご存知GoogleのWebブラウザです。
普段安定版を使っているので、今回のスクレイピングではbetaやDev, Canaryなどのバージョンをインストールして実行環境を分けようかと思っていたのですが、バージョンが頻繁に変わる関係上、ChromeDriverとの相性などから安定版(Stable)を使うこととしました。
Python
せっかく大学の必修の授業で習ったし、深層学習で海美と恵美の顔を見分ける記事でも使ったので今回はPythonで書きました。
バージョンが若干古いのはTensorflow-gpuが最新バージョンに対応してなかっただけで特に理由はありません。
Selenium
Webブラウザの操作を自動化するためのフレームワーク。
Pythonにはpipで導入できます。
$ pip install selenium
実は公式のDockerイメージを使った方が楽らしいのですが、Docker for Windowsで色々と苦しんだ経験があるため、今回はローカルに環境を構築しています。
ChromeDriver
Webブラウザの操作をするにはSeleniumとブラウザに加え、ブラウザ別のWebDriverを導入する必要があります。
今回はGoogle Chromeを使うので、Chrome用のWebDriverであるChromeDriverを導入しました。
ChromeDriverもpip経由で導入できます。
注意としてChromeDriverのバージョンはChromeのバージョンと対応しているため、インストールの際にはChromeブラウザのバージョンを確認する必要があります。
今回はバージョン80.0.3987.106.0を使用します。
$ pip install chromedriver-binary==80.0.3987.106.0
Beatiful Soup
ブラウザで取得したWebページのhtmlを解析するためのツールとして今回はBeautiful Soupを使用します。
$ pip install beautifulsoup4
Beautiful Soup自体はhtmlパーサーでは無く、パーサーのラッパーのように働くので、別途htmlパーサーを用意する必要があります。
lxml
Pythonには標準でhtml.parserというパーサーが含まれていますが、動作の速度などの観点から、今回はlxmlをインストールして使用します。
$ pip install lxml
requests
今回はHTTPのGETリクエストを送って画像をダウンロードしようとしているので、リクエストを送信するためのライブラリを導入します。
Pythonに標準で入っているurllibを使うこともできるのですが、サードパーティーライブラリのrequestsを使って楽をしました。
$ pip install requests
実装
こういうコードを書きました。抜粋して解説を書いておきます。
設定系
url = 'https://app.slack.com/client/example/example'
now = datetime.datetime.now()
# ループを終了する時間を設定
timer = now + datetime.timedelta(minutes=30)
# 画像保存先ディレクトリ
# ディレクトリ名は実行時刻から設定
dir_name = "./imgs_{0:%Y%m%d}_{0:%H%M}".format(now)
# Chromeのユーザープロファイルのパスを指定
profile_path = "D:/workspace/slack-selenium/user"
冒頭では画像を取得する先のURLや、画像の保存先ディレクトリを指定しています。
Slackのワークスペースへのログイン情報を使いまわすために、今回はユーザープロファイルの保存先を宣言しています。
Chromeの起動オプション
# 起動オプション指定
options = webdriver.ChromeOptions()
# 使用するChromeの実行ファイルへのパス。
# StableとBetaなど複数VerのChromeがインストールされている場合に必要?
# options.binary_location = "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe"
# Cookieなどを何度も使いまわすためにユーザープロファイルを指定する
options.add_argument('--user-data-dir='+profile_path)
options.add_argument('--profile-directory=Default')
# 少しでも動作を軽くしたいので拡張機能とWebフォントをoff
options.add_argument('--disable-extensions')
options.add_argument('--disable-remote-fonts')
# headlessで起動するためのオプション
# ユーザープロファイルとの両立がうまくいかなかったため今回はコメントアウト
# options.add_argument('--headless')
# options.add_argument('--disable-gpu')
# options.add_argument("--no-sandbox")
# options.add_argument("--window-size=1280x1696")
次にChromeを起動する時のオプションを宣言します。
ChromeはGUIを表示しないheadlessモードでの起動が可能であり、処理の高速化の面で有利なのですが、ユーザープロファイルの保存と両立させる方法がわからなかったため、今回はコメントアウトしています。
html取得・解析
while True: # 無限ループ
# 読み込みが終わるのを1sec待つ
time.sleep(1)
html = driver.page_source
body = driver.find_element_by_css_selector('body')
# 取得したhtmlをBeautifulSoupに渡して解析
soup = BeautifulSoup(html, "lxml")
今回は無限スクロールが可能なページのスクレイピングを行うため、無限ループを回してhtmlを解析しています。
html = driver.page_source でブラウザが取得したhtmlを soup = BeautifulSoup(html, "lxml")でBeautiful Soupに渡しています。この時引数でlxmlをhtmlパーサーとして使用することを宣言しています。
画像への直リンクを探す
その後htmlソースから目的のファイルを抽出していくのですが、ここで目的のファイルを絞りこむ方法を考える必要があります。
Google Chromeの開発者ツールを使って埋め込み画像のあたりのhtmlソースを見てみます。
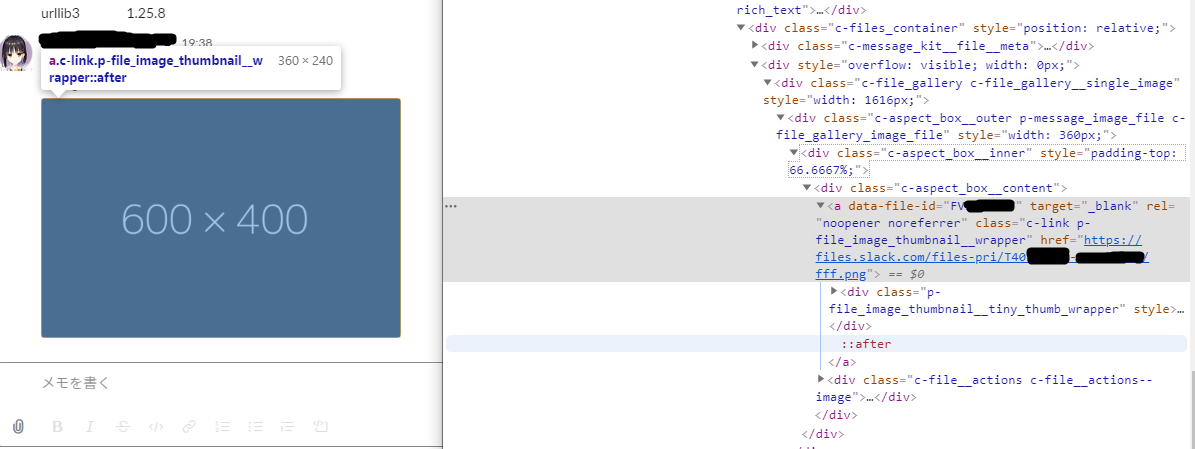
SlackのWebページのソースを読むと、埋め込まれている画像は"c-link p-file_image_thumbnail__wrapper"というクラスの付いたa要素となっている事が分かります。
<a data-file-id="FVXXXXXXX" target="_blank" rel="noopener noreferrer" class="c-link p-file_image_thumbnail__wrapper"
href="https://files.slack.com/files-pri/T40XXXXXX-XXXXXXXXX/fff.png">
<div class="p-file_image_thumbnail__tiny_thumb_wrapper" style="">
<img class="p-file_image_thumbnail__image" alt="fff.png"
src="https://files.slack.com/files-tmb/T40XXXXXX-XXXXXXXXXXX-XXXXXXX/fff_480.png">
</div>
</a>
またこのa要素のリンク先(href属性で指定されている)は投稿された画像のオリジナルへの直リンクとなっています。
という訳で"c-link p-file_image_thumbnail__wrapper"というクラスの付いたa要素のhref属性値のURLを収集していけば、投稿された画像をオリジナルサイズで集めることができそうです。
# 渡されたhtmlからclass名とタグを指定して要素を抽出, 配列化
imgs = soup.find_all("a", class_="c-link p-file_image_thumbnail__wrapper")
# 該当する要素が無かった場合はループ終了
if imgs is None:
break
requestsにCookieを渡す
こうしてa要素の配列が出来たところで各要素内のURLにGETリクエストを送っていく訳ですが、Slackのチャンネルに投稿された画像にはそのチャンネルの閲覧権限があるアカウントにログインしていないとアクセスすることができません。
SlackのWeb版ではCookieでログインセッションを保持しているので、リクエストを送るrequestsライブラリにChromeが持っているCookieを渡してあげることで、画像にアクセスできるようにします。
なおsave_countは後ほど使う無限ループの終了判定用変数です。
session = requests.session()
# ChromeからrequestsにCookieを渡す
# これにより非ログイン時に閲覧不可能な画像もDLできる
for cookie in driver.get_cookies():
session.cookies.set(cookie["name"], cookie["value"])
# ループ終了判定用の変数を初期化
# 保存した画像の数をカウント
save_count = 0
画像をGETして保存
画像のGETリクエストを送る準備ができたので、いよいよ画像のDLに移っていきます。
for img in imgs:
# a要素からhrefのリンク先を抽出
url = img.get('href')
fname_list = url.split("/")
# URLの一番後ろからファイル名、後ろから二番目からハッシュ値を取得
fname = str(fname_list[-2]) + "_" + str(fname_list[-1])
save_path = dir_name + "/" + fname
まずはこちらで配列の要素となっているa要素から、href属性の値、つまりリンク先を抽出しています。
その後URLの末尾2つ(ファイル名とその一つ上のディレクトリ名)を繋げて、保存に使うファイル名として変数化しておきます。
一つ上のディレクトリ名がハッシュ値っぽいので、これによって同名ファイルを判別できるようになります。
# 既に同名ファイルがある場合は保存しない
if not os.path.isfile(save_path):
save_count += 1
responce = session.get(url)
with open(save_path, "wb") as f:
f.write(responce.content)
print("Downloaded " + fname)
次に条件式で同名ファイルが存在しないことを確認して、存在しない場合にGETリクエストを送ります。
その後返ってきたファイルをwith openで保存することで、ファイルをダウンロードすることができます。
またこのタイミングでループ終了判定用の変数save_countを加算しています。
終了判定
ここまで何度か出てきたループ終了判定用の変数を使って、無限ループを続けるかどうか判定を行います。
# 一つも新規ファイルが保存できなかった場合
if save_count == 0:
# no_imgを1加算
no_img += 1
else:
# no_imgをリセット
no_img = 0
# 三回連続で新規ファイルが無かった場合
# ループ終了
if no_img >= 3:
break
# 設定した時間が経過した場合
# ループ終了
if datetime.datetime.now() >= timer:
break
ファイルの保存成功時にsave_countを加算しているので、一枚も新規ファイルが無かった場合にはsave_countは0となります。
その場合に変数no_imgを加算し、no_imgが3になった時、つまり3回連続で新規ファイルが見つからなかった場合にbreakでループを終了します。
また冒頭で”(冒頭での)現在時刻 + 任意の分数”を変数timerとしておき、timerと比べて現在時刻の方が後だった場合にループを終了するというクソ雑なタイマー機能を実装しています。
スクロール
次が懸念事項だった画面のスクロール。
SlackはJSで無限スクロールを実装していて、htmlの中身が動的に書き換えられていくのでリンクを辿っていく通常の手法ではスクレイピングができません。
またスクロールについてもページ内の各エリアにスクロールバーが表示されることから、Webブラウザ側ではなくページ側でスクロールをしているように思われます。(このへん適当に書いています)
これらの事情からどうやってスクロールをしようか悩んでいたのですが、結局のところはかなり簡単に解決できました。
その方法がPageUpキーを押すというもの。
Seleniumでは特殊キーを押す操作も実行できるので、ページのbodyにフォーカスした状態でPageUpを押して画面をスクロールし、過去の投稿を読み込ませることができます。
# PgUpキーを2回押してスクロール
body.send_keys(Keys.PAGE_UP)
body.send_keys(Keys.PAGE_UP)
あとはここまでのコードをwhile文で回せば、どんどん投稿を遡って保存できます。
終わりに
このコードを実行したところ、無事にたくさんの画像を保存することができました。
ひとまず成功して良かったです。
反省点
- 遅い
- まあPythonだしwhileとか使ってるし…
- C#からでもSeleniumは使えるので、そっちにした方が速いかもしれませんね
- そもそもスクレイピングしていいのか
- 一応閲覧・DL権限のあるユーザーだから不正とまではいかないが、そもそもスクレイピング自体がそんなに好ましく無さそう
- 幸か不幸か実行速度が遅いのでサーバーに問題が生じるほどの負担はかからなそう
- クソ眠くて記事の後半の記述が雑
- Civが悪いよ
結論
管理者に頼んでSlack APIを使いましょう。
余談
最近すみぺ(上坂すみれさん)のInstagram(@uesaka_sumire)の投稿にえちみ感じ始めてヤバい。
フォローしましょう。